
Deep dive into pandas Copy-on-Write mode — part I
Deep Dive into pandas Copy-on-Write Mode: Part I
Explaining how Copy-on-Write works internally

Introduction
pandas 2.0 was released in early April and brought many improvements to the new Copy-on-Write (CoW) mode. The feature is expected to become the default in pandas 3.0, which is scheduled for April 2024 at the moment. There are no plans for a legacy or non-CoW mode.
This series of posts will explain how Copy-on-Write works internally to help users understand what’s going on, show how to use it effectively and illustrate how to adapt your code. This will include examples on how to leverage the mechanism to get the most efficient performance and also show a couple of anti-patterns that will result in unnecessary bottlenecks. I wrote a short introduction to Copy-on-Write a couple of months ago.
I wrote a short post that explains the data structure of pandas which will help you understand some terminology that is necessary for CoW.
I am part of the pandas core team and was heavily involved in implementing and improving CoW so far. I am an open source engineer for Coiled where I work on Dask, including improving the pandas integration and ensuring that Dask is compliant with CoW.
How Copy-on-Write changes pandas behavior
Many of you are probably familiar with the following caveats in pandas:
import pandas as pd
df = pd.DataFrame({"student_id": [1, 2, 3], "grade": ["A", "C", "D"]})
Let’s select the grade-column and overwrite the first row with “E”.
grades = df["grade"]
grades.iloc[0] = "E"
df
student_id grade
0 1 E
1 2 C
2 3 D
Unfortunately, this also updated df and not only grades, which has the potential to introduce hard to find bugs. CoW will disallow this behavior and ensures that only df is updated. We also see a false-positive SettingWithCopyWarning that doesn’t help us here.
Let’s look at a ChainedIndexing example that is not doing anything:
df[df["student_id"] > 2]["grades"] = "F"
df
student_id grade
0 1 A
1 2 C
2 3 D
We again get a SettingWithCopyWarning but nothing happens to df in this example. All these gotchas come down to copy and view rules in NumPy, which is what pandas uses under the hood. pandas users have to be aware of these rules and how they apply to pandas DataFrames to understand why similar code patterns produce different results.
CoW cleans up all these inconsistencies. Users can only update one object at a time when CoW is enabled, e.g. df would be unchanged in our first example since only grades is updated at that time and the second example raises a ChainedAssignmentError instead of doing nothing. Generally, it won’t be possible to update two objects at once, e.g., every object behaves as it is a copy of the previous object.
There are many more of these cases, but going through all of them is not in scope here.
How it works
Let’s look into Copy-on-Write in more detail and highlight some facts that are good to know. This is the main part of this post and is fairly technical.
Copy-on-Write promises that any DataFrame or Series derived from another in any way always behaves as a copy. This means that it is not possible to modify more than one object with a single operation, e.g. our first example above would only modify grades.
A very defensive approach to guarantee this would be to copy the DataFrame and its data in every operation, which would avoid views in pandas altogether. This would guarantee CoW semantics but also incur a huge performance penalty, so this wasn’t a viable option.
We will now dive into the mechanism that ensures that no two objects are updated with a single operation and that our data isn’t unnecessarily copied. The second part is what makes the implementation interesting.
We have to know exactly when to trigger a copy to avoid copies that aren’t absolutely necessary. Potential copies are only necessary if we try to mutate the values of one pandas object without copying its data. We have to trigger a copy, if the data of this object is shared with another pandas object. This means that we have to keep track of whether one NumPy array is referenced by two DataFrames (generally, we have to be aware if one NumPy array is referenced by two pandas objects, but I will use the term DataFrame for simplicity).
df = pd.DataFrame({"student_id": [1, 2, 3], "grade": [1, 2, 3]})
df2 = df[:]
This statement creates a DataFrame df and a view of this DataFrame df2. View means that both DataFrames are backed by the same underlying NumPy array. When we look at this with CoW, df has to be aware that df2 references its NumPy array too. This is not sufficient though. df2 also has to be aware that df references its NumPy array. If both objects are aware that there is another DataFrame referencing the same NumPy array, we can trigger a copy in case one of them is modified, e.g.:
df.iloc[0, 0] = 100
df is modified inplace here. df knows that there is another object that references the same data, e.g. it triggers a copy. It is not aware which object references the same data, just that there is another object out there.
Let’s take a look at how we can achieve this. We created an internal class BlockValuesRefs that is used to store this information, it points to all DataFrames that reference a given NumPy array.
There are three different types of operation that can create a DataFrame:
- A DataFrame is created from external data, e.g. through pd.DataFrame(…) or through any I/O method.
- A new DataFrame is created through a pandas operation that triggers a copy of the original data, e.g. dropna creates a copy in almost all cases.
- A new DataFrames is created through a pandas operation that does not trigger a copy of the original data, e.g. df2 = df.reset_index().
The first two cases are simple. When the DataFrame is created, the NumPy arrays that back it are connected to a fresh BlockValuesRefs object. These arrays are only referenced by the new object, so we don’t have to keep track of any other objects. The object creates a weakref that points to the Block that wraps the NumPy array and stores this reference internally. The concept of Blocks is explained here.
A weakref creates a reference to any Python object. It does not keep this object alive when it would normally go out of scope.
import weakref
class Dummy:
def __init__(self, a):
self.a = a
In[1]: obj = Dummy(1)
In[2]: ref = weakref.ref(obj)
In[3]: ref()
Out[3]:
In[4]: obj = Dummy(2)
This example creates a Dummy object and a weak reference to this object. Afterward, we assign another object to the same variable, e.g. the initial object goes out of scope and is garbage collected. The weak reference does not interfere with this process. If you resolve the weak reference, it will point to None instead of the original object.
In[5]: ref()
Out[5]: None
This ensures that we don’t keep any arrays alive that would otherwise be garbage collected.
Let’s take a look at how these objects are organized:
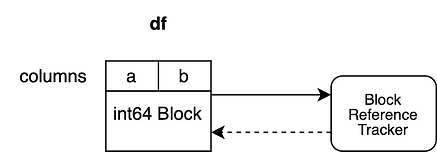
Our example has two columns “a” and “b” which both have dtype “int64”. They are backed by one Block that holds the data for both columns. The Block holds a hard reference to the reference tracking object, ensuring that it stays alive as long as the Block is not garbage collected. The reference tracking object holds a weak reference to the Block. This enables the object to track the lifecycle of this block but does not prevent garbage collection. The reference tracking object does not hold a weak reference to any other Block yet.
These are the easy scenarios. We know that no other pandas object shares the same NumPy array, so we can simply instantiate a new reference tracking object.
The third case is more complicated. The new object views the same data as the original object. This means that both objects point to the same memory. Our operation will create a new Block that references the same NumPy array, this is called a shallow copy. We now have to register this new Block in our reference tracking mechanism. We will register our new Block with the reference tracking object that is connected to the old object.
df2 = df.reset_index(drop=True)
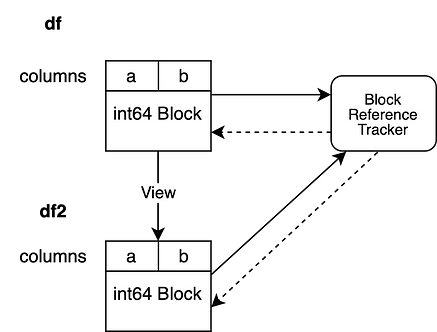
Our BlockValuesRefs now points to the Block that backs the initial df and the newly created Block that backs df2. This ensures that we are always aware about all DataFrames that point to the same memory.
We can now ask the reference tracking object how many Blocks pointing to the same NumPy array are alive. The reference tracking object evaluates the weak references and tells us that more than one object references the same data. This enables us to trigger a copy internally if one of them is modified in place.
df2.iloc[0, 0] = 100
The Block in df2 is copied through a deep copy, creating a new Block that has its own data and reference tracking object. The original block that was backing df2 can now be garbage collected, which ensures that the arrays backing df and df2 don’t share any memory.
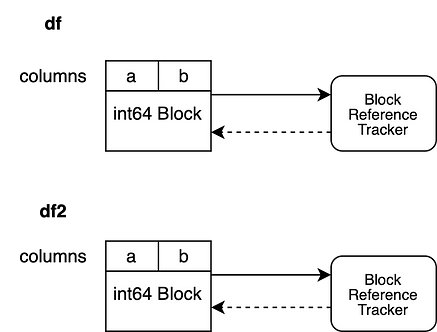
Let’s look at a different scenario.
df = None
df2.iloc[0, 0] = 100
df is invalidated before we modify df2. Consequently, the weakref of our reference tracking object, that points to the Block that backed df, evaluates to None. This enables us to modify df2 without triggering a copy.
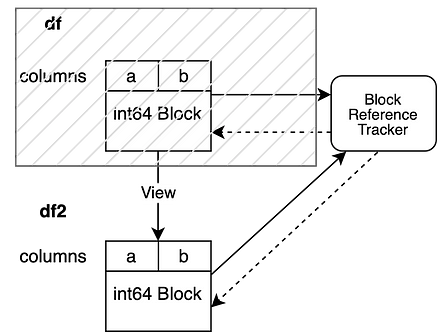
Our reference tracking object points to only one DataFrame which enables us to do the operation inplace without triggering a copy.
reset_index above creates a view. The mechanism is a bit simpler if we have an operation that triggers a copy internally.
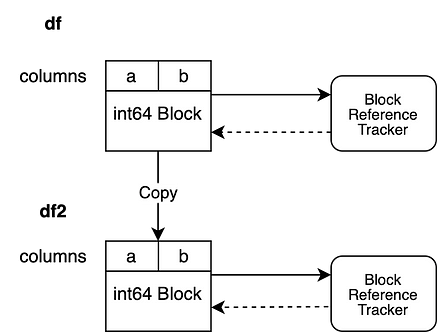
df2 = df.copy()
This immediately instantiates a new reference tracking object for our DataFrame df2.
Conclusion
We have investigated how the Copy-on-Write tracking mechanism works and when we trigger a copy. The mechanism defers copies in pandas as much as possible, which is quite different from the non-CoW behavior. The reference tracking mechanism keeps track of all DataFrames that share memory, enabling more consistent behavior in pandas.
The next part in this series will explain techniques that are used to make this mechanism more efficient.
Thank you for reading. Feel free to reach out to share your thoughts and feedback about Copy-on-Write.
Deep dive into pandas Copy-on-Write mode — part I was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.




