
Bypassing the GIL for Parallel Processing in Python
Unlocking Python’s true potential in terms of speed through shared-memory parallelism has traditionally been limited and challenging to achieve. That’s because the global interpreter lock (GIL) doesn’t allow for thread-based parallel processing in Python. Fortunately, there are several work-arounds for this notorious limitation, which you’re about to explore now!
In this tutorial, you’ll learn how to:
- Run Python threads in parallel on multiple CPU cores
- Avoid the data serialization overhead of multiprocessing
- Share memory between Python and C runtime environments
- Use different strategies to bypass the GIL in Python
- Parallelize your Python programs to improve their performance
- Build a sample desktop application for parallel image processing
To get the most out of this advanced tutorial, you should understand the difference between concurrency and parallelism. You’ll benefit from having previous experience with multithreading in programming languages other than Python. Finally, it’s best if you’re eager to explore uncharted territory, such as calling foreign Python bindings or writing bits of C code.
Don’t worry if your knowledge of parallel processing is a bit rusty, as you’ll have a chance to quickly refresh your memory in the upcoming sections. Also, note that you’ll find all the code samples, image files, and the demo project from this tutorial in the supporting materials, which you can download below:
Get Your Code: Click here to download the free sample code that shows you how to bypass the GIL and achieve parallel processing in Python.
Recall the Fundamentals of Parallel Processing
Before dipping your toes into specific ways of bypassing the GIL in Python, you might want to revisit some related topics. Over the following few sections, you’ll familiarize yourself with different computer processing models, task types, abstractions over modern CPUs, and some history. If you already know this information, then feel free to jump ahead to the classic mechanism for parallelization in Python.
What’s Parallel Processing?
Under Flynn’s taxonomy, the most common types of parallel processing allow you to run the same (SIMD) or different code fragments (MIMD) in separate execution streams at the same time:
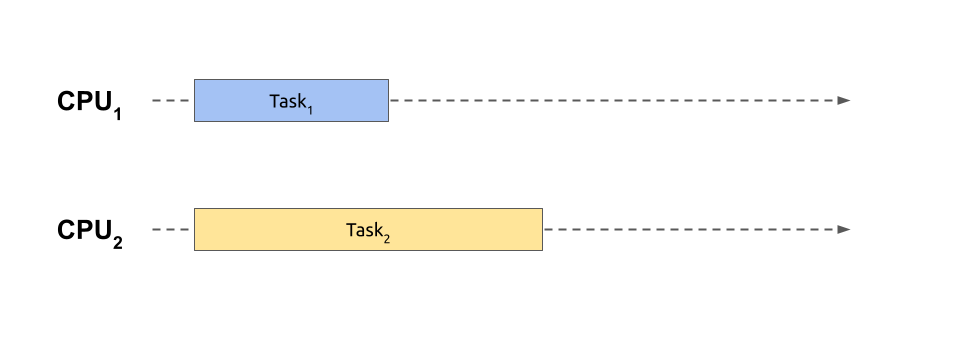
Here, two independent tasks or jobs execute alongside each other. To run more than one piece of code simultaneously like this, you need a computer equipped with a central processing unit (CPU) comprising multiple physical cores, which is the norm nowadays. While you could alternatively access a cluster of geographically distributed machines, you’ll consider only the first option in this tutorial.
Parallel processing is a particular form of concurrent processing, which is a broader term encompassing context switching between multiple tasks. It means that a currently running task might voluntarily suspend its execution or be forcibly suspended to give a slice of the CPU time to another task:
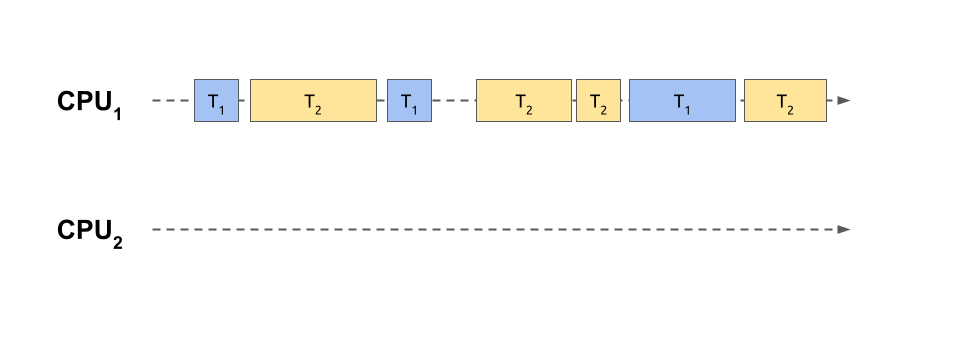
In this case, two tasks have been sliced into smaller and intertwined chunks of work that share a single core of the same processing unit. This is analogous to playing chess against multiple opponents at the same time, as shown in one of the scenes from the popular TV miniseries The Queen’s Gambit. After each move, the player proceeds to the next opponent in a round-robin fashion, trying to remember the state of the corresponding game.
Note: Context switching makes multitasking possible on single-core architectures. However, multi-core CPUs also benefit from this technique when the tasks outnumber the available processing power, which is often the case. Therefore, concurrent processing usually involves spreading the individual task slices over many CPUs, combining the power of context switching and parallel processing.
While it takes time for people to switch their focus, computers take turns much quicker. Rapid context switching gives the illusion of parallel execution despite using only one physical CPU. As a result, multiple tasks are making progress together.
Because of time-sharing, the total time required to finish your intertwined tasks running concurrently is longer when compared to a genuinely parallel version. In fact, context switching has a noticeable overhead that makes the execution time even worse than if you run your tasks one after another using sequential processing on a single CPU. Here’s what sequential processing looks like:
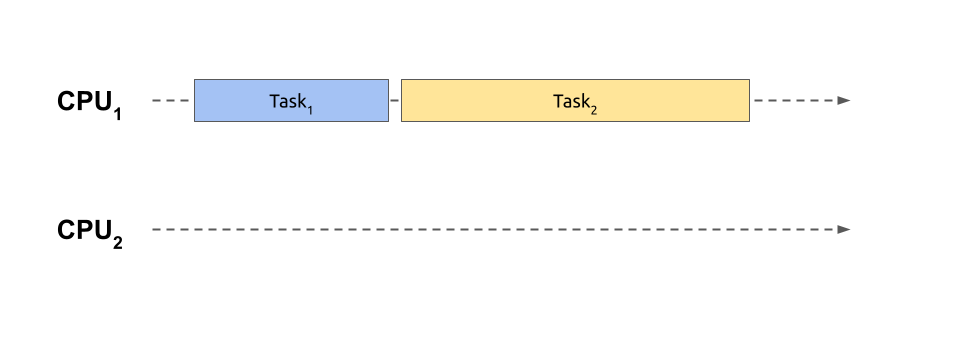
With sequential processing, you don’t start another task until the previous one finishes, so you don’t have the costs of switching back and forth. This situation corresponds to playing an entire chess game with one opponent before moving on to the next one. Meanwhile, the remaining players must sit tight, patiently waiting for their turn.
On the other hand, playing multiple games concurrently can maximize your throughput. When you prioritize games with players who make quick decisions over those who need more time to think, then you’ll finish more games sooner. Therefore, intertwining can improve the latency, or response times, of the individual tasks, even when you only have one stream of execution.
As you can probably tell, choosing between parallel, concurrent, and sequential processing models can feel like plotting out your next three moves in chess. You have to consider several factors, so there’s no one-size-fits-all solution.
Whether context switching actually helps will depend on how you prioritize your tasks. Inefficient task scheduling can lead to starving shorter tasks of CPU time.
Additionally, the types of tasks are critical. Two broad categories of concurrent tasks are CPU-bound and I/O-bound ones. The CPU-bound tasks will only benefit from truly parallel execution to run faster, whereas I/O-bound tasks can leverage concurrent processing to reduce latency. You’ll learn more about these categories’ characteristics now.
How Do CPU-Bound and I/O-Bound Tasks Differ?
Read the full article at https://realpython.com/python-parallel-processing/ »
[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]




