
LLMOps: Production prompt engineering patterns with Hamilton
LLMOps: Production Prompt Engineering Patterns with Hamilton
An overview of the production-grade ways to iterate on prompts with Hamilton

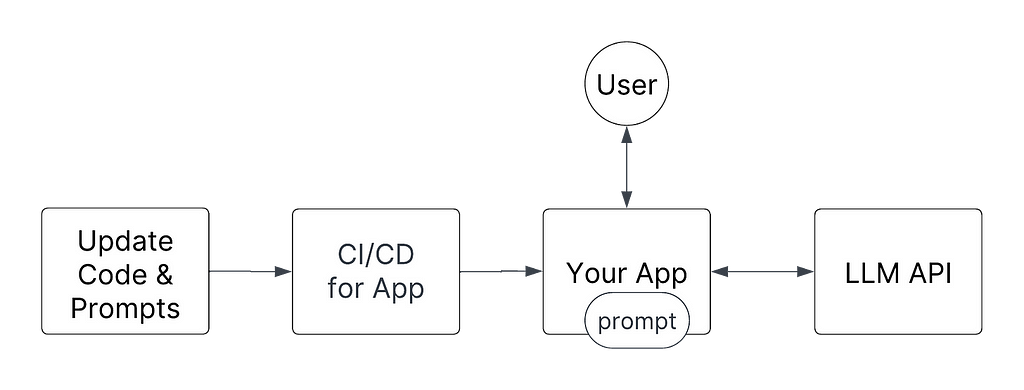
What you send to your large language model (LLM) is quite important. Small variations and changes can have large impacts on outputs, so as your product evolves, the need to evolve your prompts will too. LLMs are also constantly being developed and released, and so as LLMs change, your prompts will also need to change. Therefore it’s important to set up an iteration pattern to operationalize how you “deploy” your prompts so you and your team can move efficiently, but also ensure that production issues are minimized, if not avoided. In this post, we’ll guide you through the best practices of managing prompts with Hamilton, an open source micro-orchestration framework, making analogies to MLOps patterns, and discussing trade-offs along the way. The high level takeaways of this post are still applicable even if you don’t use Hamilton.
A few things before we start:
- I am one of the co-creators of Hamilton.
- Not familiar with Hamilton? Scroll all the way to the bottom for more links.
- If you’re looking for a post that talks about “context management” this isn’t that post. But it is the post that will help you with the nuts and bolts on how to iterate and create that production grade “prompt context management” iteration story.
- We’ll use prompt & prompt template interchangeably.
- We’ll assume an “online” web-service setting is where these prompts are being used.
- We’ll be using our Hamilton’s PDF summarizer example to project our patterns onto.
- What’s our credibility here? We’ve spent our careers building self-service data/MLOps tooling, most famously for Stitch Fix’s 100+ Data Scientists. So we’ve seen our share of outages and approaches play out over time.
Prompts are to LLMs what hyper-parameters are to ML models
Point: Prompts + LLM APIs are analogous to hyper-parameters + machine learning models.
In terms of “Ops” practices, LLMOps is still in its infancy. MLOps is a little older, but still neither are widely adopted if you’re comparing it to how widespread knowledge is around DevOps practices.
DevOps practices largely concern themselves with how you ship code to production, and MLOps practices how to ship code & data artifacts (e.g., statistical models) to production. So what about LLMOps? Personally, I think it’s closer to MLOps since you have:
- your LLM workflow is simply code.
- and an LLM API is a data artifact that can be “tweaked” using prompts, similar to a machine learning (ML) model and its hyper-parameters.
Therefore, you most likely care about versioning the LLM API + prompts together tightly for good production practices. For instance, in MLOps practice, you’d want a process in place to validate your ML model still behaves correctly whenever its hyper-parameters are changed.
How should you think about operationalizing a prompt?
To be clear, the two parts to control for are the LLM and the prompts. Much like MLOps, when the code or the model artifact changes, you want to be able to determine which did. For LLMOps, we’ll want the same discernment, separating the LLM workflow from the LLM API + prompts. Importantly, we should consider LLMs (self-hosted or APIs) to be mostly static since we less frequently update (or even control) their internals. So, changing the prompts part of LLM API + prompts is effectively like creating a new model artifact.
There are two main ways to treat prompts:
- Prompts as dynamic runtime variables. The template used isn’t static to a deployment.
- Prompts as code. The prompt template is static/ predetermined given a deployment.
The main difference is the amount of moving parts you need to manage to ensure a great production story. Below, we dig into how to use Hamilton in the context of these two approaches.
Prompts as dynamic runtime variables
Dynamically Pass/Load Prompts
Prompts are just strings. Since strings are a primitive type in most languages, this means that they are quite easy to pass around. The idea is to abstract your code so that at runtime you pass in the prompts required. More concretely, you’d “load/reload” prompt templates whenever there’s an “updated” one.
The MLOps analogy here, would be to auto-reload the ML model artifact (e.g., a pkl file) whenever a new model is available.
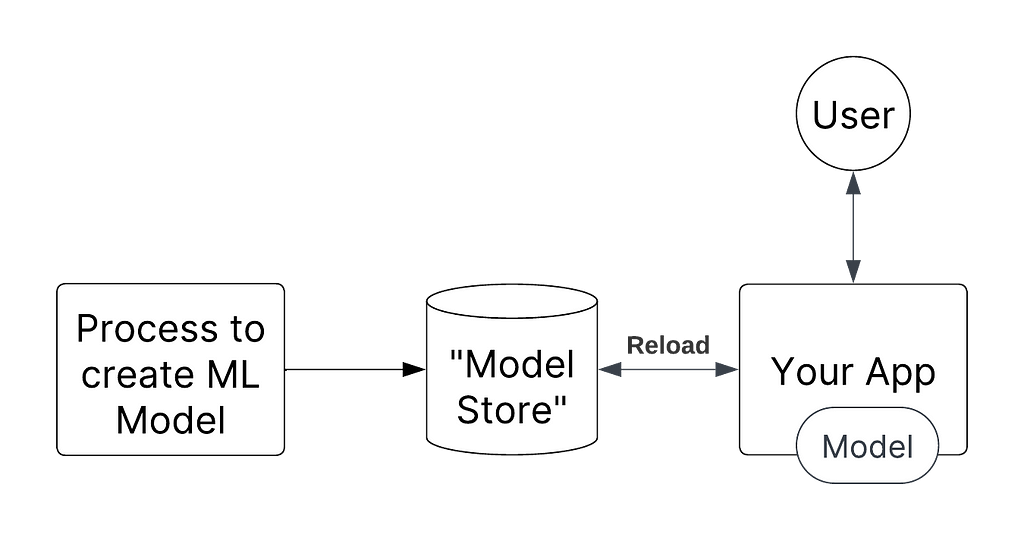
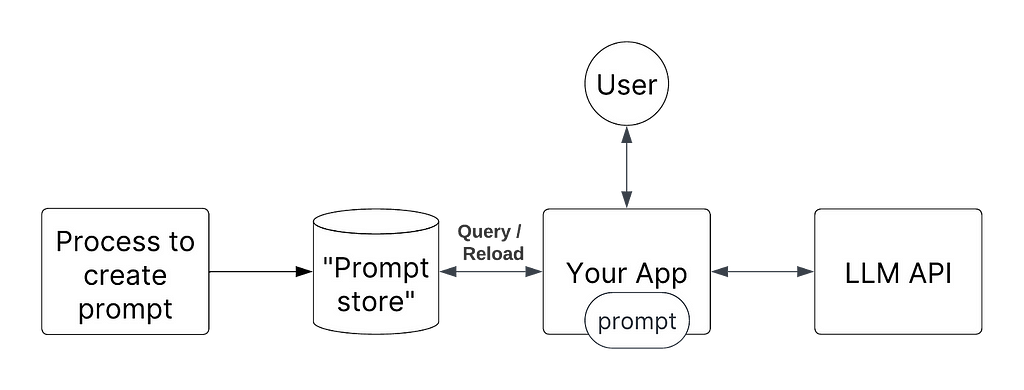
The benefit here is that you can very quickly roll out new prompts because you do not need to redeploy your application!
The downside to this iteration speed is increased operational burden:
- To someone monitoring your application, it’ll be unclear when the change occurred and whether it’s propagated itself through your systems. For example, you just pushed a new prompt, and the LLM now returns more tokens per request, causing latency to spike; whoever is monitoring will likely be puzzled, unless you have a great change log culture.
- Rollback semantics involve having to know about another system. You can’t just rollback a prior deployment to fix things.
- You’ll need great monitoring to understand what was run and when; e.g., when customer service gives you a ticket to investigate, how do you know what prompt was in use?
- You’ll need to manage and monitor whatever system you’re using to manage and store your prompts. This will be an extra system you’ll need to maintain outside of whatever is serving your code.
- You’ll need to manage two processes, one for updating and pushing the service, and one for updating and pushing prompts. Synchronizing these changes will be on you. For example, you need to make a code change to your service to handle a new prompt. You will need to coordinate changing two systems to make it work, which is extra operational overhead to manage.
How it would work with Hamilton
Our PDF summarizer flow would look something like this if you remove summarize_text_from_summaries_prompt and summarize_chunk_of_text_prompt function definitions:
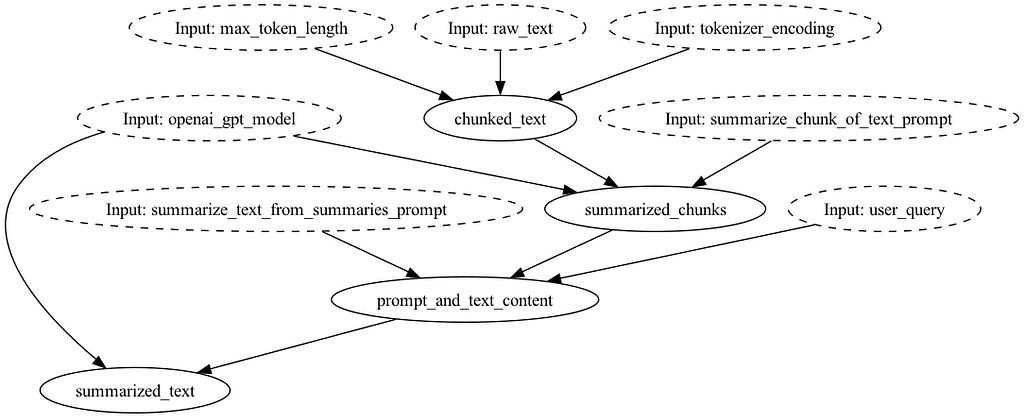
To operate things, you’ll want to either inject the prompts at request time:
from hamilton import base, driver
import summarization_shortend
# create driver
dr = (
driver.Builder()
.with_modules(summarization_sortened)
.build()
)
# pull prompts from somewhere
summarize_chunk_of_text_prompt = """SOME PROMPT FOR {chunked_text}"""
summarize_text_from_summaries_prompt = """SOME PROMPT {summarized_chunks} ... {user_query}"""
# execute, and pass in the prompt
result = dr.execute(
["summarized_text"],
inputs={
"summarize_chunk_of_text_prompt": summarize_chunk_of_text_prompt,
...
}
)
Or you change your code to dynamically load prompts, i.e., add functions to retrieve prompts from an external system as part of the Hamilton dataflow. At each invocation, they will query for the prompt to use (you can of course cache this for performance):
# prompt_template_loaders.py
def summarize_chunk_of_text_prompt(
db_client: Client, other_args: str) -> str:
# pseudo code here, but you get the idea:
_prompt = db_client.query(
"get latest prompt X from DB", other_args)
return _prompt
def summarize_text_from_summaries_prompt(
db_client: Client, another_arg: str) -> str:
# pseudo code here, but you get the idea:
_prompt = db_client.query(
"get latest prompt Y from DB", another_arg)
return _prompt
Driver code:
from hamilton import base, driver
import prompt_template_loaders # <-- load this to provide prompt input
import summarization_shortend
# create driver
dr = (
driver.Builder()
.with_modules(
prompt_template_loaders,# <-- Hamilton will call above functions
summarization_sortened,
)
.build()
)
# execute, and pass in the prompt
result = dr.execute(
["summarized_text"],
inputs={
# don't need to pass prompts in this version
}
)
How would I log prompts used and monitor flows?
Here we outline a few ways to monitor what went on.
- Log results of execution. That is run Hamilton, then emit information to wherever you want it to go.
result = dr.execute(
["summarized_text",
"summarize_chunk_of_text_prompt",
... # and anything else you want to pull out
"summarize_text_from_summaries_prompt"],
inputs={
# don't need to pass prompts in this version
}
)
my_log_system(result) # send what you want for safe keeping to some
# system that you own.
Note. In the above, Hamilton allows you to request any intermediate outputs simply by requesting “functions” (i.e. nodes in the diagram) by name. If we really want to get all the intermediate outputs of the entire dataflow, we can do so and log it wherever we want to!
- Use loggers inside Hamilton functions (to see the power of this approach, see my old talk on structured logs):
import logging
logger = logging.getLogger(__name__)
def summarize_text_from_summaries_prompt(
db_client: Client, another_arg: str) -> str:
# pseudo code here, but you get the idea:
_prompt = db_client.query(
"get latest prompt Y from DB", another_arg)
logger.info(f"Prompt used is [{_prompt}]")
return _prompt
- Extend Hamilton to emit this information. You use Hamilton to capture information from executed functions, i.e. nodes, without needing to insert logging statement inside the function’s body. This promotes reusability since you can toggle logging between development and production settings at the Driver level. See GraphAdapters, or write your own Python decorator to wrap functions for monitoring.
In any of the above code, you could easily pull in a 3rd party tool to help track & monitor the code, as well as the external API call.
Prompts as code
Prompts as static strings
Since prompts are simply strings, they’re also very amenable to being stored along with your source code. The idea is to store as many prompt versions as you like within your code so that at runtime, the set of prompts available is fixed and deterministic.
The MLOps analogy here is, instead of dynamically reloading models, you instead bake the ML model into the container/hard code the reference. Once deployed, your app has everything that it needs. The deployment is immutable; nothing changes once it’s up. This makes debugging & determining what’s going on, much simpler.
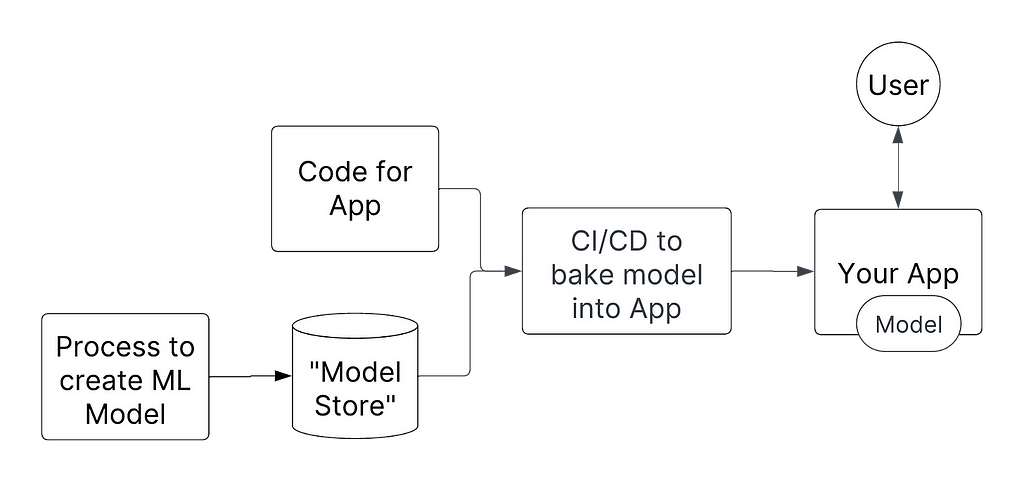
This approach has many operational benefits:
- Whenever a new prompt is pushed, it forces a new deployment. Rollback semantics are clear if there’s an issue with a new prompt.
- You can submit a pull request (PR) for the source code and prompts at the same time. It becomes simpler to review what the change is, and the downstream dependencies of what these prompts will touch/interact with.
- You can add checks to your CI/CD system to ensure bad prompts don’t make it to production.
- It’s simpler to debug an issue. You just pull the (Docker) container that was created and you’ll be able to exactly replicate any customer issue quickly and easily.
- There is no other “prompt system” to maintain or manage. Simplifying operations.
- It doesn’t preclude adding extra monitoring and visibility.
How it would work with Hamilton
The prompts would be encoded into functions into the dataflow/directed acyclic graph (DAG):
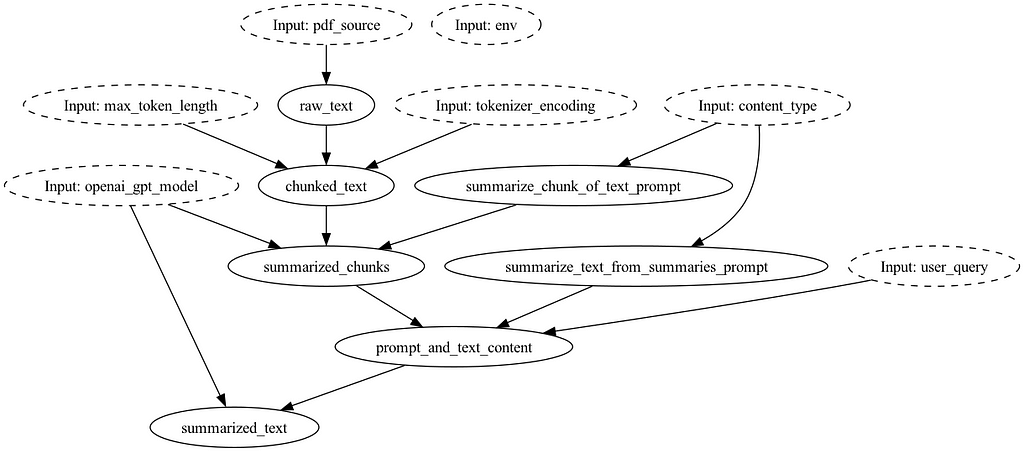
Pairing this code with git, we have a lightweight versioning system for your entire dataflow (i.e. “chain”), so you can always discern what state the world was in, given a git commit SHA. If you want to manage and have access to multiple prompts at any given point in time, Hamilton has two powerful abstractions to enable you to do so: @config.when and Python modules. This allows you to store and keep available all older prompt versions together and specify which one to use via code.
@config.when (docs)
Hamilton has a concept of decorators, which are just annotations on functions. The @config.when decorator allows to specify alternative implementations for a functions, i.e. “node”, in your dataflow. In this case, we specify alternative prompts.
from hamilton.function_modifiers import config
@config.when(version="v1")
def summarize_chunk_of_text_prompt__v1() -> str:
"""V1 prompt for summarizing chunks of text."""
return f"Summarize this text. Extract any key points with reasoning.nnContent:"
@config.when(version="v2")
def summarize_chunk_of_text_prompt__v2(content_type: str = "an academic paper") -> str:
"""V2 prompt for summarizing chunks of text."""
return f"Summarize this text from {content_type}. Extract the key points with reasoning. nnContent:"
You can keep adding functions annotated with @config.when, allowing you to swap between them using configuration passed to the Hamilton Driver. When instantiating the Driver, it will construct the dataflow using the prompt implementation associated with the configuration value.
from hamilton import base, driver
import summarization
# create driver
dr = (
driver.Builder()
.with_modules(summarization)
.with_config({"version": "v1"}) # V1 is chosen. Use "v2' for V2.
.build()
)
Module switching
Alternatively to using @config.when, you can instead place your different prompt implementations into different Python modules. Then, at Driver construction time, pass the correct module for the context you want to use.
So here we have one module housing V1 of our prompt:
# prompts_v1.py
def summarize_chunk_of_text_prompt() -> str:
"""V1 prompt for summarizing chunks of text."""
return f"Summarize this text. Extract any key points with reasoning.nnContent:"
Here we have one module housing V2 (see how they differ slightly):
# prompts_v2.py
def summarize_chunk_of_text_prompt(content_type: str = "an academic paper") -> str:
"""V2 prompt for summarizing chunks of text."""
return f"Summarize this text from {content_type}. Extract the key points with reasoning. nnContent:"
In the driver code below, we choose the right module to use based on some context.
# run.py
from hamilton import driver
import summarization
import prompts_v1
import prompts_v2
# create driver -- passing in the right module we want
dr = (
driver.Builder()
.with_modules(
prompts_v1, # or prompts_v2
summarization,
)
.build()
)
Using the module approach allows us to encapsulate and version whole sets of prompts together. If you want to go back in time (via git), or see what a blessed prompt version was, you just need to navigate to the correct commit, and then look in the right module.
How would I log prompts used and monitor flows?
Assuming you’re using git to track your code, you wouldn’t need to record what prompts were being used. Instead, you’d just need to know what git commit SHA is deployed and you’ll be able to track the version of your code and prompts simultaneously.
To monitor flows, just like the above approach, you have the same monitoring hooks available at your disposal, and I wont repeat them here, but they are:
- Request any intermediate outputs and log them yourself outside of Hamilton.
- Log them from within the function yourself, or build a Python decorator / GraphAdapter to do it at the framework level.
- Integrate 3rd party tooling for monitoring your code and LLM API calls.
- or all the above!
What about A/B testing my prompts?
With any ML initiative, it’s important to measure business impacts of changes. Likewise, with LLMs + prompts, it’ll be important to test and measure changes against important business metrics. In the MLOps world, you’d be A/B testing ML models to evaluate their business value by dividing traffic between them. To ensure the randomness necessary to A/B tests, you wouldn’t know at runtime which model to use until a coin is flipped. However, to get those models out, they both would have follow a process to qualify them. So for prompts, we should think similarly.
The above two prompt engineering patterns don’t preclude you from being able to A/B test prompts, but it means you need to manage a process to enable however many prompt templates you’re testing in parallel. If you’re also adjusting code paths, having them in code will be simpler to discern and debug what is going on, and you can make use of the `@config.when` decorator / python module swapping for this purpose. Versus, having to critically rely on your logging/monitoring/observability stack to tell you what prompt was used if you’re dynamically loading/passing them in and then having to mentally map which prompts go with which code paths.
Note, this all gets harder if you start needing to change multiple prompts for an A/B test because you have several of them in a flow. For example you have two prompts in your workflow and you’re changing LLMs, you’ll want to A/B test the change holistically, rather than individually per prompt. Our advice, by putting the prompts into code your operational life will be simpler, since you’ll know what two prompts belong to what code paths without having to do any mental mapping.
Summary
In this post, we explained two patterns for managing prompts in a production environment with Hamilton. The first approach treats prompts as dynamic runtime variables, while the second, treats prompts as code for production settings. If you value reducing operational burden, then our advice is to encode prompts as code, as it is operationally simpler, unless the speed to change them really matters for you.
To recap:
- Prompts as dynamic runtime variables. Use an external system to pass the prompts to your Hamilton dataflows, or use Hamilton to pull them from a DB. For debugging & monitoring, it’s important to be able to determine what prompt was used for a given invocation. You can integrate open source tools, or use something like the DAGWorks Platform to help ensure you know what was used for any invocation of your code.
- Prompts as code. Encoding the prompts as code allows easy versioning with git. Change management can be done via pull requests and CI/CD checks. It works well with Hamilton’s features like @config.when and module switching at the Driver level because it determines clearly what version of the prompt is used. This approach strengthens the use of any tooling you might use to monitor or track, like the DAGWorks Platform, as prompts for a deployment are immutable.
We want to hear from you!
If you’re excited by any of this, or have strong opinions, leave a comment, or drop by our Slack channel! Some links to do praise/complain/chat:
- 📣 join our community on Slack — we’re more than happy to help answer questions you might have or get you started.
- ⭐️ us on GitHub.
- 📝 leave us an issue if you find something.
- 📚 read our documentation.
- ⌨️ interactively learn about Hamilton in your browser.
Other Hamilton links/posts you might be interested in:
- tryhamilton.dev — an interactive tutorial in your browser!
- Hamilton + Lineage in 10 minutes
- How to use Hamilton with Pandas in 5 Minutes
- How to use Hamilton with Ray in 5 minutes
- How to use Hamilton in a Notebook environment
- General backstory & introduction on Hamilton
- The perks of creating dataflows with Hamilton (Organic user post on Hamilton!)
LLMOps: Production prompt engineering patterns with Hamilton was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.



