
What Is Keras Core?
Table of Contents
What Is Keras Core?
In this tutorial, you will learn about Keras Core, the new Keras Team repository that allows switching from the Keras backend to TensorFlow, PyTorch, and JAX.

This lesson introduces Keras Core and its multi-backend functionalities.
To learn how to navigate the Keras Core library, just keep reading.
What Is Keras Core?
In short, Keras Core is the first effort to end the 100-year war of Deep Learning Frameworks and unite forces for a better and “open” artificial intelligence (AI) future.
We are obviously joking, but our opening statement is not completely untrue. To quote the actual definition from the Keras Core repository:
Keras Core is a new multi-backend implementation of the Keras API, with support for TensorFlow, JAX, and PyTorch.
This means you can switch your backends like Iron Man switching his suits as and when he needs them. But the only difference is, you are not limited to just Iron Man suits, but also Batman, Green Lantern, and Blue Beetle … you get the point.
If you are already sold and need to see some cold hard proof (code examples), jump to the next section.
However, read on if you are interested in recapping Keras and understanding how keras_core came to be.
Configuring Your Development Environment
To follow this guide, you need to have the keras-core library installed on your system.
Luckily, keras-core is pip-installable:
$ pip install keras-core
Let’s Talk about Keras!

First, let’s clarify what Keras is. Keras is a user-friendly tool written in Python for Deep Learning. It’s designed to be used with TensorFlow, another major player in the AI field.
Think of Keras as your personal assistant in the realm of machine learning. Its job is to make your life as a developer easier and more efficient. Here are some reasons why Keras is so cool:
- It’s User-friendly: Keras strives to reduce your workload, allowing you to focus on the bigger picture. It’s designed to be easy to use, quick for debugging, elegant and concise in coding, maintainable, and easily deployable.
- It’s Adaptable: Keras believes in starting simple and gradually unveiling complexity. The idea is to make basic tasks quick and easy and allow for more complex tasks to be accomplished step by step.
- It’s Powerful: Keras delivers professional-grade performance and scalability. Impressive, right? Big names like NASA, YouTube, and Waymo trust it. This means your YouTube video suggestions and some of the most sophisticated self-driving vehicles rely on Keras.
In short, Keras’s blend of simplicity and extensibility makes it an attractive starting point for everyone, from AI novices to seasoned deep learning engineers.
Going Beyond with Keras Core

But, it would be amazing if we could do more. How about creating models that can train on any data pipeline and run on any platform? Enter Keras Core!
Keras Core is a new and improved version of Keras. It supports multiple platforms, including TensorFlow, JAX, and PyTorch. It’s intended to be a drop-in replacement for tf.keras when using the TensorFlow backend.
If you have a tf.keras model that doesn’t include custom components, you can effortlessly switch it to run on JAX or PyTorch. Even if it does include custom components, you can usually tweak it to work with any backend in just a few minutes.
Plus, Keras Core models can digest datasets in any format, no matter what backend you’re using. You can train your models with existing tf.data.Dataset pipelines or Torch DataLoaders.
So, Keras is evolving beyond a conventional deep learning framework. It’s becoming a code-based User Interface where you can toggle between different backends, features, and components to make your work easier. Imagine having a LEGO set of machine learning tools — Keras Core lets you construct massive, complex systems from simple, interchangeable components.
The Power of Keras Core: Expanding Your Deep Learning Horizons

Seamless Framework Switching: With Keras Core, you’re no longer tied to one framework. You can effortlessly shift your high-level Keras workflows between TensorFlow, JAX, PyTorch, and others. Fancy the scalability of JAX or the production-ready features of TensorFlow? With Keras Core, you’re free to enjoy the best of both worlds.
Custom Components Across Frameworks: Need a custom layer, model, or metric? Keras Core lets you integrate custom components that work across all frameworks, aiding in developing unique solutions for your deep learning challenges.
Universal Training Loops: Keras Core allows you to train a Keras model using a training loop crafted from scratch in TensorFlow, JAX, or PyTorch. This flexibility ensures your model is trained most efficiently for your particular project.
Integration with Native Models: Keras Core extends flexibility by letting you incorporate a Keras model as part of a PyTorch-native Module or a JAX-native model function. This means you can smoothly integrate the advantages of Keras with your existing PyTorch or JAX workflows.
Future-Proof Code: With Keras Core, you can make your machine learning code future-proof, evading the risk of being locked into a single framework.
Boosting User Experience: PyTorch users, rejoice! Keras Core lets you tap into the powerful and user-friendly nature of Keras. JAX users, you’re not left out either! Keras Core provides you with a fully equipped, battle-hardened, and well-documented modeling and training library.
In essence, Keras Core elevates your deep learning experience, delivering a versatile and flexible tool geared for your success.
Show Me Some Code
Wow! That is some neat engineering work done by the Keras team. Let’s dive deeper into the package, see how to switch backends, and take full advantage of the keras_core.
Let’s start with installing the package.
Keras Core is compatible with the Linux and MacOS systems. To install a local development version:
pip install -r requirements.txtpython pip_build.py --install
Note that Keras Core strictly requires TensorFlow, particularly because it uses tf.nest to handle nested Python structures. In the future, the repository will most likely make all backend frameworks optional.
Now that you have the package installed, let’s talk about the backend first. To configure your backend, export the environment variable KERAS_BACKEND or edit your local config file at ~/.keras/keras.json. Available backend options are: “tensorflow”, “jax”, and “torch”. Example:
export KERAS_BACKEND="jax"
Now we know that we can switch backends with the KERAS_BACKEND environment variable. So, what is stopping us from changing the backend inside a Python script?
import os os.environ["KERAS_BACKEND"] = "jax"
Neat, isn’t it?
Now for the fun part. If you are a PyImageSearch reader, you will remember the blog post series on JAX.
- Learning JAX in 2023: Part 1 — The Ultimate Guide to Accelerating Numerical Computation and Machine Learning
- Learning JAX in 2023: Part 2 — JAX’s Power Tools
grad,jit,vmap, andpmap - Learning JAX in 2023: Part 3 — A Step-by-Step Guide to Training Your First Machine Learning Model with JAX
We also covered an Image Classification model in JAX, where we talked about writing a custom train step and building the model using Flax.
Let us address the elephant in the room. JAX is good because it is fast. It allows you to run your experiments in jet speed (jit compilation), but writing a custom train step and using another library (Flax) for modeling is like embracing an unorganized airport with no signs (poor design and documentation of Flax) before boarding your jet.
You could skip all of that and actually go to the runway and board the jet with your familiar car.
In Deep Learning terms, this means having the ability to use the Keras modeling and training APIs while using JAX functions for speedup and gradient calculations!
JAX Harnessing model.fit()
A note of credit: The official guide at Keras Core repository heavily inspired the following example.
Imports and Setup
import os os.environ["KERAS_BACKEND"] = "jax" import keras_core import jax import tensorflow as tf import tensorflow_datasets as tfds from matplotlib import pyplot as plt
We set the KERAS_BACKEND environment variable to “jax”. This is done for us to use JAX as the backend for keras_core.
The other imports are necessary for this example.
Data Pipeline
train_ds, val_ds, test_ds = tfds.load(
"cifar10",
split=["train[:90%]", "train[90%:]", "test"]
)
This line loads the CIFAR-10 dataset and splits it into 90% for training (train_ds), 10% for validation (val_ds), and the original test set for testing (test_ds).
def map_fn(inputs):
image = tf.cast(inputs["image"], "float32") / 255.
label = inputs["label"]
return image, label
This function, map_fn, is used to preprocess the inputs from the CIFAR-10 dataset:
image = tf.cast(inputs["image"], "float32") / 255.: It takes the “image” field from the inputs, casts it tofloat32data type, and normalizes the pixel values to the range[0, 1]by dividing by255.label = inputs["label"]: It takes the “label” field from the inputs, which represents the class of the image.
The function returns a tuple of the processed image and its corresponding label.
train_ds = (
train_ds
.map(map_fn)
.shuffle(32 * 10)
.batch(32)
.prefetch(tf.data.AUTOTUNE)
)
val_ds = (
val_ds
.map(map_fn)
.shuffle(32 * 10)
.batch(32)
.prefetch(tf.data.AUTOTUNE)
)
test_ds = (
test_ds
.map(map_fn)
.batch(32)
.prefetch(tf.data.AUTOTUNE)
)
These lines of code apply transformations to the training, validation, and test datasets:
.map(map_fn): Applies themap_fnfunction to each element in the dataset. This function scales the images and extracts the labels..shuffle(32 * 10): Shuffles the dataset. This is important for the training dataset to ensure the model gets data randomly. The number32 * 10is the buffer size for the shuffle operation. Notice how we do not shuffle thetest_ds..batch(32): Batches the dataset into groups of 32. This means that the model will update its weights after seeing 32 samples..prefetch(tf.data.AUTOTUNE): Prefetches the data for faster consumption. It allows the dataset to asynchronously fetch batches while the model is training.tf.data.AUTOTUNEallows TensorFlow to automatically choose the number of batches to prefetch based on available resources, optimizing for throughput.
The training and validation datasets are shuffled, but the test dataset is not because shuffling has no effect during model evaluation.
Build a Custom Model
In a JAX workflow, the training and testing steps are designed to be stateless, meaning they don’t maintain any internal state. Instead, the state is passed explicitly as a parameter to these functions. This approach differs from traditional workflows where the state (like model weights or optimizer state) is maintained internally and updated in place (stateful).
The state typically includes the trainable parameters of the model, non-trainable parameters, and the optimizer state. It is updated after each step and passed back. This explicit handling of state is beneficial for parallel and distributed computing where maintaining and synchronizing internal state can be challenging.
In the training step, the state is used to compute the model’s predictions, calculate the loss, and update the model parameters using backpropagation. The updated state is then returned.
In the testing step, the state is used to compute the model’s predictions on the test data. The state remains unchanged during testing as we don’t perform any updates to the model parameters.
This stateless design, combined with JAX’s functional programming approach, provides a flexible and efficient way to implement complex machine learning workflows.
class CustomModel(keras_core.Model):
def compute_loss_and_updates(
self,
trainable_variables,
non_trainable_variables,
x,
y,
training=False,
):
y_pred, non_trainable_variables = self.stateless_call(
trainable_variables,
non_trainable_variables,
x,
training=training,
)
loss = self.compute_loss(x, y, y_pred)
return loss, (y_pred, non_trainable_variables)
The above code snippet defines a custom model class CustomModel that inherits from keras_core.Model.
The compute_loss_and_updates method is a custom method that calculates the loss and updates the model’s variables. Here’s what it does:
y_pred, non_trainable_variables = self.stateless_call(trainable_variables, non_trainable_variables, x, training=training): This line computes the model’s predictions (y_pred) given the inputs (x) and the current state of trainable and non-trainable variables. Thestateless_callmethod is a feature of Keras Core that allows for stateless computation of the model’s forward pass.loss = self.compute_loss(x, y, y_pred): This line computes the loss using a methodcompute_lossthat you would need to define in yourCustomModelclass. It takes the true labels (y), the model’s predictions (y_pred), and the inputs (x).return loss, (y_pred, non_trainable_variables): The method returns the computed loss and a tuple containing the model’s predictions and the updated non-trainable variables.
This setup allows for a clear separation of the forward pass, loss computation, and the updates to the model’s variables, providing a flexible framework for customizing the training process.
def train_step(self, state, data):
# Unpack the current state
(
trainable_variables,
non_trainable_variables,
optimizer_variables,
metrics_variables,
) = state
# Unpack the data
x, y = data
# Get the gradient function.
grad_fn = jax.value_and_grad(
self.compute_loss_and_updates, has_aux=True
)
# Compute the gradients.
(loss, (y_pred, non_trainable_variables)), grads = grad_fn(
trainable_variables,
non_trainable_variables,
x,
y,
training=True,
)
# Update trainable variables and optimizer variables.
(
trainable_variables,
optimizer_variables,
) = self.optimizer.stateless_apply(
optimizer_variables, grads, trainable_variables
)
# Update metrics.
new_metrics_vars = []
for metric in self.metrics:
this_metric_vars = metrics_variables[
len(new_metrics_vars) : len(new_metrics_vars)
+ len(metric.variables)
]
if metric.name == "loss":
this_metric_vars = metric.stateless_update_state(
this_metric_vars, loss
)
else:
this_metric_vars = metric.stateless_update_state(
this_metric_vars, y, y_pred
)
logs = metric.stateless_result(this_metric_vars)
new_metrics_vars += this_metric_vars
# Return metric logs and updated state variables.
state = (
trainable_variables,
non_trainable_variables,
optimizer_variables,
new_metrics_vars,
)
return logs, state
This code defines the train_step method for the CustomModel class. This method is responsible for performing a single training step, including forward pass, loss computation, backpropagation, and updating the model parameters and metrics. Here’s a breakdown:
- The current state of the model and the data for this step are passed as arguments. The state includes trainable, non-trainable, optimizer, and metrics variables.
- The
jax.value_and_gradfunction is used to create a function (grad_fn) that computes both the value of thecompute_loss_and_updatesfunction and its gradients with respect to the trainable variables. - The gradients are computed by calling
grad_fnwith the current trainable and non-trainable variables and the data. The function also returns the loss and the updated non-trainable variables. - The
stateless_applymethod of the optimizer is then used to update the trainable and optimizer variables using the computed gradients. - The metrics are updated by iterating over each metric in the model’s metrics. For each metric, its state variables are updated using its
stateless_update_statemethod, and the result is computed using itsstateless_resultmethod. - Finally, the method returns the logs (containing the metric results) and the updated state.
This method encapsulates a single step of the training process in a stateless manner, making it compatible with JAX’s functional programming model.
def test_step(self, state, data):
# Unpack the data.
x, y = data
(
trainable_variables,
non_trainable_variables,
metrics_variables,
) = state
# Compute predictions and loss.
y_pred, non_trainable_variables = self.stateless_call(
trainable_variables,
non_trainable_variables,
x,
training=False,
)
loss = self.compute_loss(x, y, y_pred)
# Update metrics.
new_metrics_vars = []
for metric in self.metrics:
this_metric_vars = metrics_variables[
len(new_metrics_vars) : len(new_metrics_vars)
+ len(metric.variables)
]
if metric.name == "loss":
this_metric_vars = metric.stateless_update_state(
this_metric_vars, loss
)
else:
this_metric_vars = metric.stateless_update_state(
this_metric_vars, y, y_pred
)
logs = metric.stateless_result(this_metric_vars)
new_metrics_vars += this_metric_vars
# Return metric logs and updated state variables.
state = (
trainable_variables,
non_trainable_variables,
new_metrics_vars,
)
return logs, state
This code defines the test_step method for the CustomModel class. This method is responsible for performing a single step of evaluation or testing. Here’s a breakdown:
- The current state of the model and the data for this step are passed as arguments. The state includes trainable variables, non-trainable variables, and metrics variables.
- The
stateless_callmethod of the model is used to compute the predictions and update the non-trainable variables. - The loss is computed using the
compute_lossmethod of the model. - The metrics are updated by iterating over each metric in the model’s metrics. For each metric, its state variables are updated using its
stateless_update_statemethod, and the result is computed using itsstateless_resultmethod. - Finally, the method returns the logs (containing the metric results) and the updated state.
This method encapsulates a single step of the testing process in a stateless manner, making it compatible with JAX’s functional programming model.
Build the Image Classification Model
conv2d_kwargs = {
"kernel_size": (3, 3),
"activation": "relu",
"padding": "same",
}
This line creates a dictionary conv2d_kwargs with parameters for a 2D convolutional layer. It specifies a 3×3 kernel size, ReLU activation, and the same padding to maintain input dimensions.
inputs = keras_core.Input(shape=(32, 32, 3), name="input_layer")
x = inputs
for filters in [32, 64, 128]:
x = keras_core.layers.Conv2D(filters=filters, **conv2d_kwargs)(x)
x = keras_core.layers.BatchNormalization()(x)
x = keras_core.layers.Conv2D(filters=filter, strides=(2, 2), **conv2d_kwargs)(x)
x = keras_core.layers.BatchNormalization()(x)
x = keras_core.layers.Dropout(0.25)(x)
x = keras_core.layers.GlobalAveragePooling2D()(x)
x = keras_core.layers.Dense(128, activation="relu")(x)
x = keras_core.layers.Dropout(0.25)(x)
outputs = keras_core.layers.Dense(10, activation="softmax", name="output_layer")(x)
Here, we construct a Convolutional Neural Network (CNN) model using Keras Core.
- It starts by defining an input layer that accepts images of shape
(32, 32, 3). - Then, it creates three blocks of layers, each consisting of two convolutional layers followed by batch normalization and dropout. The number of filters in the convolutional layers increases from
32to64to128across the blocks. - After the blocks, it applies global average pooling to the feature maps, followed by a dense layer with ReLU activation and another dropout layer.
- Finally, it adds an output layer with 10 units (for 10 classes) and softmax activation for multi-class classification.
model = CustomModel(inputs, outputs, name="image_classification_model")
model.compile(
optimizer=keras_core.optimizers.Adam(learning_rate=1e-4),
loss="sparse_categorical_crossentropy",
metrics=["accuracy"]
model.summary()
Finally, we instantiate our custom model using the Functional API of Keras. We then compile the model with the Adam optimizer, sparse categorical cross-entropy as the loss function, and accuracy as the metric for evaluation. The model’s architecture is then displayed with the model.summary() (figure below) method.
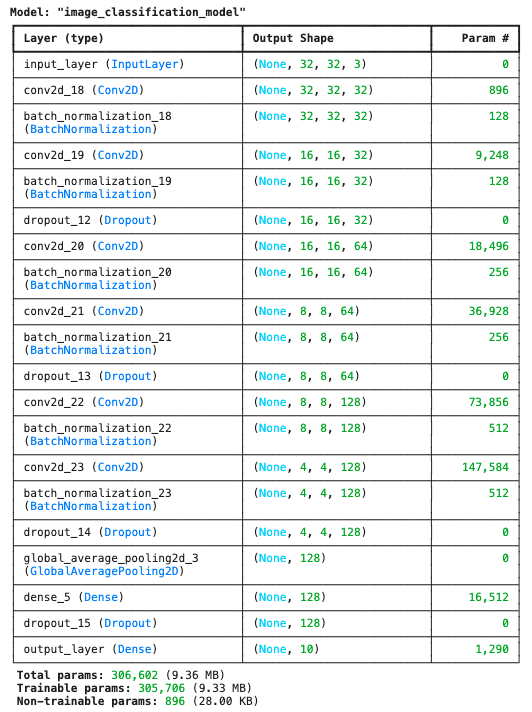
Train the Model
history = model.fit(
train_ds,
epochs=20,
validation_data=val_ds
)
And lastly, for the moment we have been waiting for, we call the legendary model.fit() on the JAX workflow. Below is a figure showing that our model is indeed training.

plt.plot(history.history["accuracy"], label="train acc")
plt.plot(history.history["val_accuracy"], label="val acc")
plt.legend()
plt.title("Accuracy Plot")
plt.show()
We generate the plot to visualize the model’s training and validation accuracy (figure below) across the epochs.
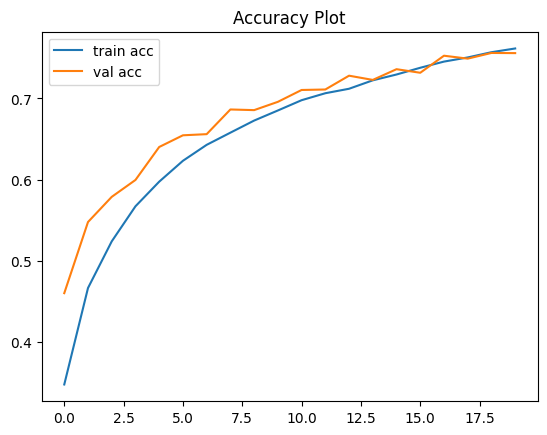
plt.plot(history.history["loss"], label="train loss")
plt.plot(history.history["val_loss"], label="val loss")
plt.legend()
plt.title("Loss Plot")
plt.show()
We generate another plot to visualize the model’s training and validation loss (figure below) across the epochs.
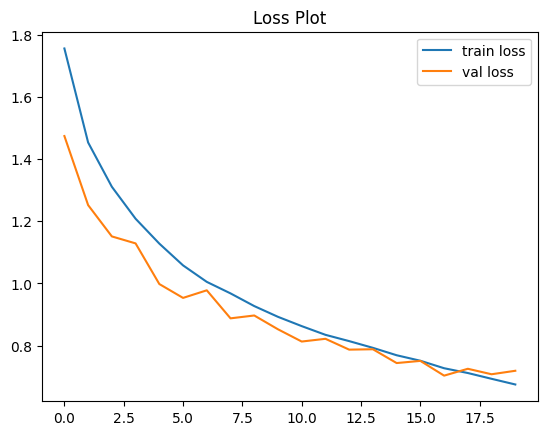
Evaluation
loss, accuracy = model.evaluate(test_ds)
print(f"{loss=:0.4f}")
print(f"{accuracy=:0.4f}")
We evaluate the model on the test dataset to measure its loss and accuracy (screenshot below in the figure), finally assessing the model’s performance.

The project output is visualized in the following gif (shown in the figure below). We can see that there are a few misclassifications, but a few classes have been predicted accurately. A pretty good feat for a model trained for only 20 epochs.

What’s next? I recommend PyImageSearch University.
78 total classes • 97+ hours of on-demand code walkthrough videos • Last updated: July 2023
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you’re serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you’ll find:
- ✓ 78 courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 78 Certificates of Completion
- ✓ 97+ hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 512+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
Alright, let’s wrap this up! In this tutorial, we unpacked a small section of things possible using Keras Core.
- Keras Core: We started by introducing Keras Core, the deep learning library that’s as adaptable as a chameleon. It can switch between TensorFlow, PyTorch, and JAX backends faster than you can say “neural network”!
- JAX: We then picked JAX as our backend of choice. Why? Because it’s like the cool new kid on the block who’s great at number crunching and loves complex computations.
- Data Loading: Next, we juggled with the CIFAR-10 dataset, splitting it into training, validation, and test sets. We also normalized and batched the data, because, let’s face it, nobody likes to train on messy data.
- Building the Model: We then played architect and built our own custom Keras model.
- JAX Workflow: We then danced with JAX workflows, integrating them into our Keras Core model. We integrated the traditional
model.fitAPI with a stateless train and test step, making our model compatible with JAX’svalue_and_gradfunction. - Model Training: After compiling our model and setting it up with the right optimizer, loss function, and metrics, we trained our model. It worked! Losses went down, accuracies went up, and Keras is now officially compatible with other frameworks like JAX.
- Model Evaluation: Finally, we put our model to the test, literally. We evaluated it on the test set to see if all that training paid off. Spoiler alert: it did!
- Visualizing Progress: And, of course, what’s a journey without some selfies along the way? We captured our model’s progress over time with some cool plots of accuracy and loss.
But with Keras Core, this is just the tip of the iceberg (sorry, Twitter thread makers). The full range of capabilities now includes:
- Mix and Match: With Keras Core, you can use any framework you choose. You can enjoy the speed and scalability of JAX or the production-ready features of TensorFlow. It’s like having your cake and eating it too!
- Custom Creations: You can write your own components, like layers, models, or metrics. Then, you can use these in any framework. It’s like making and using your own Lego blocks in any Lego set.
- Training Flexibility: You can train a Keras model in any framework. Whether you’re a TensorFlow, JAX, or PyTorch fan, Keras Core has got you covered.
- Integration Ease: You can take a Keras model and integrate it into a PyTorch or JAX model. It’s like adding a new player to your favorite sports team.
- Future-Proofing: With Keras Core, you’re not locked into one framework. This means your code is ready for whatever the future of machine learning brings.
- For PyTorch Users: If you’re a PyTorch user, rejoice! You can now enjoy the power and user-friendliness of Keras.
- For JAX Users: If you’re a JAX user, good news! You now have access to a robust, well-documented library for modeling and training (as you just saw).
In short, Keras Core is like a universal adapter for machine learning frameworks. It allows you to choose, customize, and integrate, making your machine learning journey smoother and more flexible.

But it is also much more than that. Keras Core is the first step a big framework has shown in joining hands and acknowledging that each framework has its strengths and weaknesses and playing as a team will let us play longer.
References
- GitHub – keras-team/keras-core: A multi-backend implementation of the Keras API, with support for TensorFlow, JAX, and PyTorch
- Keras Core: Keras for TensorFlow, JAX, and PyTorch
Citation Information
A. R. Gosthipaty and R. Raha. “What Is Keras Core?” PyImageSearch, P. Chugh, S. Huot, K. Kidriavsteva, and A. Thanki, eds., 2023, https://pyimg.co/bm6vo
@incollection{ARG-RR_2023_WhatIsKerasCore,
author = {Aritra Roy Gosthipaty and Ritwik Raha},
title = {What Is Keras Core?},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Susan Huot and Kseniia Kidriavsteva and Abhishek Thanki},
year = {2023},
url = {https://pyimg.co/bm6vo},
}

Unleash the potential of computer vision with Roboflow – Free!
- Step into the realm of the future by signing up or logging into your Roboflow account. Unlock a wealth of innovative dataset libraries and revolutionize your computer vision operations.
- Jumpstart your journey by choosing from our broad array of datasets, or benefit from PyimageSearch’s comprehensive library, crafted to cater to a wide range of requirements.
- Transfer your data to Roboflow in any of the 40+ compatible formats. Leverage cutting-edge model architectures for training, and deploy seamlessly across diverse platforms, including API, NVIDIA, browser, iOS, and beyond. Integrate our platform effortlessly with your applications or your favorite third-party tools.
- Equip yourself with the ability to train a potent computer vision model in a mere afternoon. With a few images, you can import data from any source via API, annotate images using our superior cloud-hosted tool, kickstart model training with a single click, and deploy the model via a hosted API endpoint. Tailor your process by opting for a code-centric approach, leveraging our intuitive, cloud-based UI, or combining both to fit your unique needs.
- Embark on your journey today with absolutely no credit card required. Step into the future with Roboflow.
To download the source code to this post (and be notified when future tutorials are published here on PyImageSearch), simply enter your email address in the form below!

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you’ll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!
The post What Is Keras Core? appeared first on PyImageSearch.



