
Everyone Is Talking About AI. Almost No One Is Talking About What Matters Most.
AI Is Changing Everything. Ownership Will Decide Who Benefits.
What Hardware
Do I Get!?
Tech Lowdown with Dillon Roach

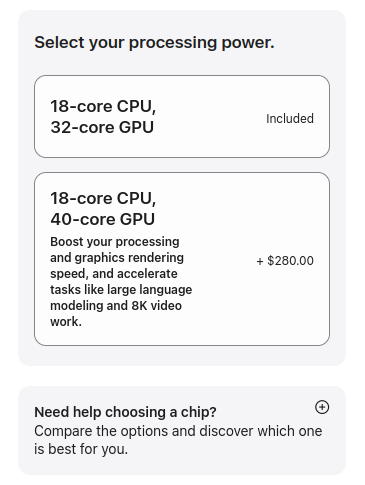
*MoE = mixture of experts, a subset of parameters are used for each token, so considerably less ‘model’ needs to be read through memory bandwidth with each new token generation.
AI Is Changing Everything. Ownership Will Decide Who Benefits.
We use cookies to improve your experience on this website. You may choose which types of cookies to allow and change your preferences at any time. Disabling cookies may impact your experience on this website. You can learn more by viewing our Cookie Policy.