I’ll be brief. I value your time. You’re in control.
For those of you following this series, I hope you’ve had the chance to go hands-on with some of the best proprietary models by now. The leading paid models are quite useful at this point and will continue to improve. But, you don’t own them – you rent them as a utility and have limited control over their behavior, availability, and handling of your private data. They’re still great services and I use them myself, but for certain things you need to run on your own hardware. What you’re able to run will naturally depend on what computer resources you have available, but I hope to at least give you some of the tools and language to help get you going.
For now, I’m going to focus on a general chat setup; agents and ‘claws’ and code interfaces can come later. Functionally, this means an app that acts as your chat interface, open model weights, and a way to run the model. For all-in-one starting points, you may want to check out one of the following three options:
The all-in-one apps will have you pretty well supported in terms of model discovery and helping sort out what models fit your device. At this particular moment in time, the Qwen3.5 or Gemma 4 model series are likely a good starting point.
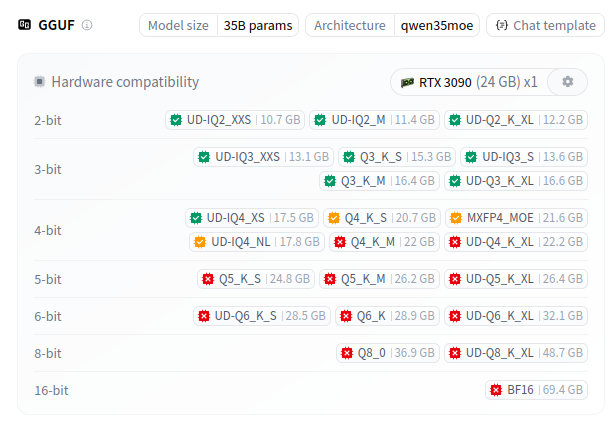
For folks feeling a bit more tech-savvy-adventurous, LibreChat or Open WebUI can serve as frontend to llama-cpp handling the model inference. In this case you’ll need to find your own models and download them yourself; taking https://huggingface.co/unsloth/Qwen3.5-35B-A3B-GGUF as an example – you’ll see in ‘Files and Versions’ that there are multiple versions of the same model saved and available. These are distinct ‘quantizations’ – different compressions of the full precision weights – you only need to download one .gguf file. The naming convention is confusing, but don’t get too caught up at first – you generally want any Q4 or above that will fit on your device. Huggingface has a size rubric for each model on the model card (example below) – anything green or yellow is a good pick, and if there’s nothing 4-bit and above that’s either, it’s likely time to go hunting for a smaller model.
As a final note – starting out, you should likely look for a Mixture-of-Experts (MoE) model, especially if you’re on an M-series Mac – these models are large in total parameters, but only use a small subset of them for each new token, so they’re fast and efficient. You’ll recognize them by the naming pattern similar to Qwen3.5-35B-A3B – the 35B is the total number of parameters (those will need to fit into memory) while the A3B says that for each token only 3B of those total 35B are active.
And as always, if you get tripped up along the way, please reach out. We love to dive into this space. It’s what we’re doing every day.